Redacting Sensitive Information
Redacting means removing or hiding part of a message so it cannot be read: you are effectively removing part of a document from your site. Typically you do this to conceal sensitive (usually, that means personal) information on the public site. Alaveteli supports an automatic form of redaction using censor rules. These can be powerful, so must be used with caution.
This page describes redaction in Alaveteli. It explains how to add censor rules, and contains a detailed example of how we use this to prevent publication of citizens’ national ID numbers in the Nicaraguan installation of Alaveteli.
Alaveteli’s redaction feature is useful because the site automatically publishes correspondence between a requester and the authority. The most common need for redaction is when one or more of the messages in that correspondence contain personal or sensitive information. Sometimes this is because the requester included personal information in the outgoing request. Often the authority, by automatically quoting the incoming email in their reply, then includes that information again in their response. This is one example; there are lots of other reasons why sensitive information might be included in messages — hence the need for redaction.
Overview of redaction
Alaveteli’s automatic redaction requires that you can predict the following. Together, these form a censor rule:
- the specific pattern of text that you want to redact
This might be a particular word, email address or number; or a particular pattern (described using a regular expression). - the replacement text
The word or words that should be used instead of the redacted text. - the range of messages to which this redaction applies
This could be all messages, or only messages relating to a specific user, or one particular request.
For example, your can tell Alaveteli to automatically replace the word swordfish
with [password redacted] in any messages relating to a request created by user Groucho
with email groucho@example.com.
These are examples of replacement texts we’ve used on WhatDoTheyKnow:
[potentially defamatory material removed]
[extraneous material removed]
[name removed]
[personal information removed]
A regular expression (regexp) is a method of pattern-matching often used by programmers, and can be used if the redaction you want is more complicated than simply matching exact text. But a regexp can be difficult to get right, especially for complex patterns. If you haven’t used them before, we recommend you learn about them first — there are a lot of resources online, including websites that let you test and experiment with your regexp before you add it to Alaveteli (for example, rubular.com). If you make a mistake in your regexp, either it won’t match when you think it should (redacting nothing), or it will match too much (redacting things that should have been left). Be careful; if you’re not sure, ask us for help first.
Alaveteli will attempt to apply redaction to attachments as well as to the text body of the message. For example, text may be redacted within PDFs or Word documents that are attached to a response to which censor rules apply.
Redaction within binary files does not use the replacement text you have
specified, because it needs to approximate the length of the text that has been
redacted. Alaveteli automatically uses [xxxxx] as the replacement text, with
as many xs as needed.
How to add a censor rule
To add a censor rule to a specific user, in the admin interface click on Users and click on their name. Scroll down to censor rules, and click New censor rule.
To add a censor rule to a specific request, click on the New censor rule button at the bottom of that request’s admin page.
To add a censor rule to a specific authority, click on the New censor rule button at the bottom of that authority’s admin page.
To add a censor rule to everything on the site, go to the Censor Rules page in
the “Tools” section of the admin navigation (or go straight to
/admin/censor_rules) and click “New global censor rule”.
If you want to redact any text that matches a particular pattern, you can use a regular expression (regexp). You need to tell Alaveteli that the text is describing such a pattern rather than the exact text you want to replace. Tick the checkbox labelled Is it a regular expression if you’re using a regexp instead of a simple, exact text match.
Basic text replacement is case sensitive — so Reading will not redact
the word reading. If you need case insensitive matching, use a regular
expression.
Enter the replacement text that should be inserted in place of the redacted
text. We recommend something like [potentially defamatory material removed]
or [personal details removed] to make it very clear that this is not the
original text and, ideally, to give some indication of why something was
redacted. Remember that the replacement text will look the same as the running
text into which it is inserted, which is why you should use square brackets, or
something like them.
Provide a comment explaining why this rule is needed. This will be seen only by other administrators on the site.
Click the create button when you are ready to add the censor rule.
Seeing unredacted text
Censor rules are applied when the site pages (which includes the admin) are displayed. If you want to see unredacted text, Alaveteli shows the original text when you edit the text of a message.
Redaction scope: requests, users, or more
The admin interface lets you easily add a censor rule to a specific request, or all requests made by a particular user.
But it’s also technically possible to add censor rules with a different scope by working directly within the source code. If you need to apply a censor rule across a broader scope, for example, for all requests on your site, ask us for help.
By way of an example, in the detailed example below, we add some code to apply a unique redaction rule to every user (for hiding their own citizen ID number).
A simple censor rule: hiding a name
The following example shows how occurrences of a specific name (“Alice”) can be hidden from messages associated with a particular request. You can also add censor rules to a user (rather than a request), so any requests they make will have the rules applied.
Add a censor rule to hide a name using an exact match
This example removes the name “Alice Alaveteli” from messages relating to a specific request.
- click on Requests in the admin interface and search or find the one you want
- click on the request’s title to go to its page in the admin
- scroll to the bottom: Censor rules
- click New censor rule and fill in the form:
- leave is it a regexp replacement unchecked because this is an exact-match word (but see the next example too)
- enter
Alice Alavetelias the “text you want to remove” - enter
[name removed]as the “replacement” - add a comment which explains the reason for the redaction (this can be read by other admins, but isn’t shown publicly)
- click on Create
The censor rule is created, and will be applied to any messages that are displayed in this request. If you look at the request’s page in the admin, you can see this rule (and any other censor rules associated with it) along with the button for creating more.
For example the text:
The witness is called Alice Alaveteli.
becomes
The witness is called [name removed].
But, because this replacement is case-sensitive, the name won’t be redacted
unless its case matches exactly (so Alice matches but alice does not). For
example, the name would not be redacted from these examples:
The witness wore a T-shirt with the words ALICE ALAVETELI on it.
Her email is alice_alaveteli@example.com
Changing a censor rule to hide a name using a regular expression
You can add more than one censor rule to the request. Alternatively, you can change one that you’ve already created. This example replaces “Alice” regardless of the case of the first letter, and even if it has double-l in the spelling.
- click on Requests in the admin interface and search or find the one you want
- click on the request’s title to go to its page in the admin interface
- scroll to the bottom: Censor rules
- find the censor rule that finds
Alice(from the previous example), click Edit and fill in the form:- tick the is it a regexp replacement checkbox because this time it is a regular expression
- enter
[Aa]ll?ice(\s+|_)[Aa]lavetelias the “text you want to remove”- in the regexp, the
[Aa]indicates any letters in the class listed, in this case,Aora - the
?signifies that the preceding item (in this case, the second letterl) is optional, and may occur “one or zero times” \s+means “one or more whitespace characters”- the arrangement of
()and a vertical bar|here means “one or more whitepace characters or an underscore”
- in the regexp, the
- keep
[name removed]as the “replacement” - update the comment which explains the reason for the modification (the name is sometimes being spelt with a double L)
- click on Create
This censor rule will match and replace the following examples:
Alice Alaveteli
and
Allice
Alaveteli
(because the line break is considered as whitespace) and also
alice_alaveteli
Note that if you can predict the specific text instead of using a regular expression, then you probably should. For example, if you expect the email to always be lower case, you could create a censor rule specifically to redact that in addition to one looking for an exact match on the capitalised name. This will probably always be more efficient than trying to capture many different things with a single regular expression.
Things to be careful about
It’s easy to make mistakes with regular expressions, so be cautious. Complex regular expressions are notoriously hard to decipher. But also remember that you are really guessing how the incoming text will appear. If anything causes the pattern not to match, then the redaction will not happen. For example:
- a phrase might break over more than one line — this becomes more likely the longer the phrase you are searching for it
- words may be hyphenated
- some documents may break the text up with (for example) formatting or markup
- writers may use alternative spellings, or mis-type words and names
- as mentioned above, some binary formats can’t be reliably redacted — they need human intervention
A detailed example
In some countries, local requirements mean that Freedom of Information requests need to contain personal details such as the address or ID number of the person asking for information. Usually requesters do not want this information to be displayed to the general public.
The following example shows how Alaveteli can help deal with this problem by automatically redacting such information using censor rules.
Nicaragua’s “General Law” (providing personal details)
This example is based on the specific requirements of
Derecho a Preguntar, the
Alaveteli site running in Nicaragua. As usual, this site is running its own
theme.
The
theme is available on github
and is called derechoapreguntar-theme.
The law in Nicaragua demands that, when a citizen makes a request, they must provide their national identity card number together with what’s known as “General Law”. Specifically, this means they must provide:
- national identity card number (“ID number”)
- date of birth
- domicile
- occupation
- marital status
In this example, we’ll show how Alaveteli collects this information, and subsequently redacts from the request pages that show the correspondence between the citizen and the authorities.
Capturing personal details at sign-up
The derechoapreguntar-theme overrides the default sign-up form by collecting
this information (because a user must sign up before their request will be
sent):
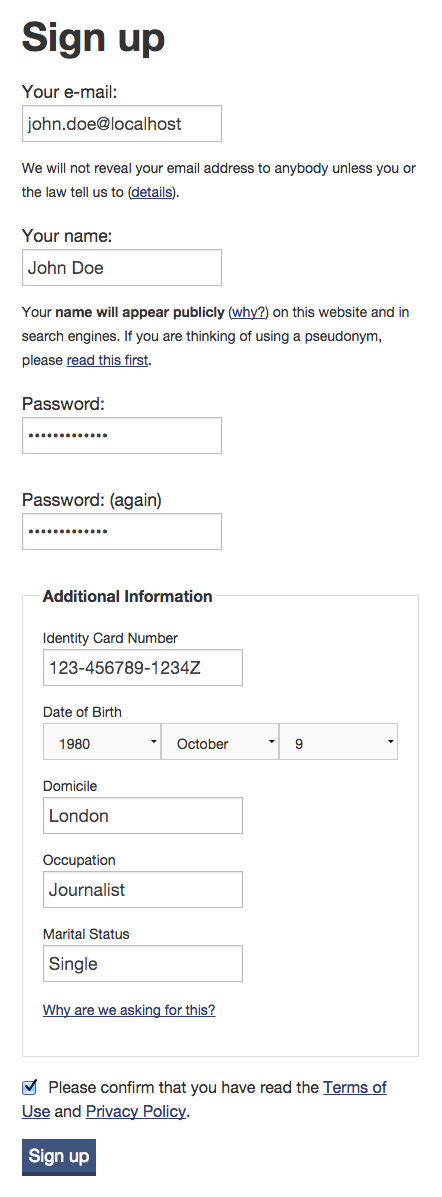
Identity card number
We’ll start off by looking at the requester’s ID number. It’s a good example of something that is relatively easy to redact because it:
- is unique for each user
- has a specified format to match against
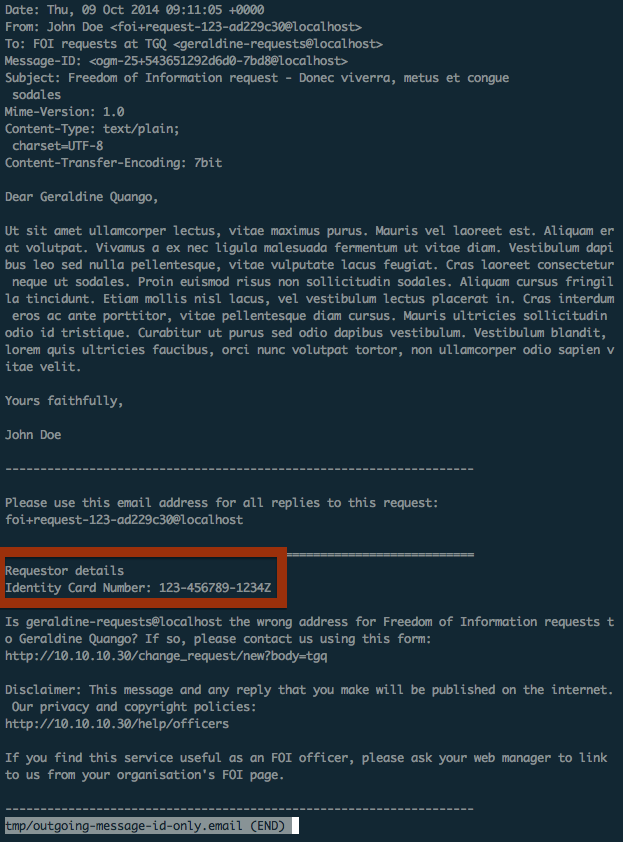
To send the ID number to the authority we override the initial request template (code snippet shortened):
<%= raw @outgoing_message.body.strip %>
-------------------------------------------------------------------
<%= _('Requestor details') %>
<%= _('Identity Card Number') %>: <%= @user_identity_card_number %>
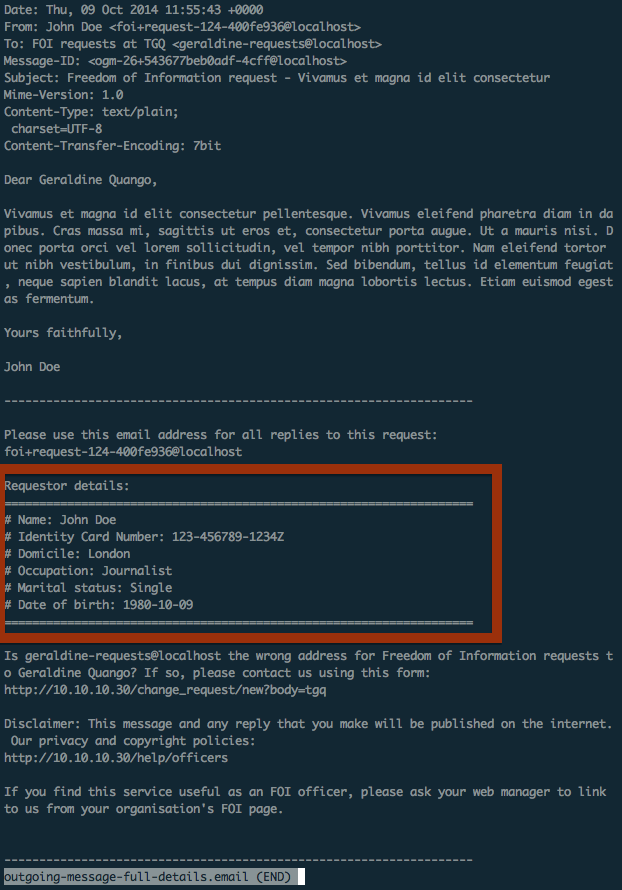
When a request is made the user’s ID number is automatically included in the footer of the outgoing email:
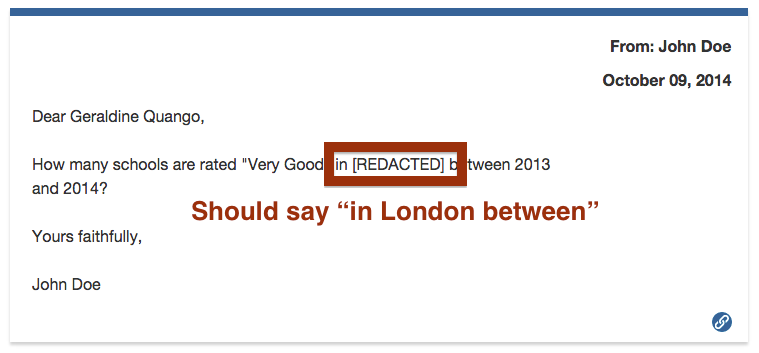
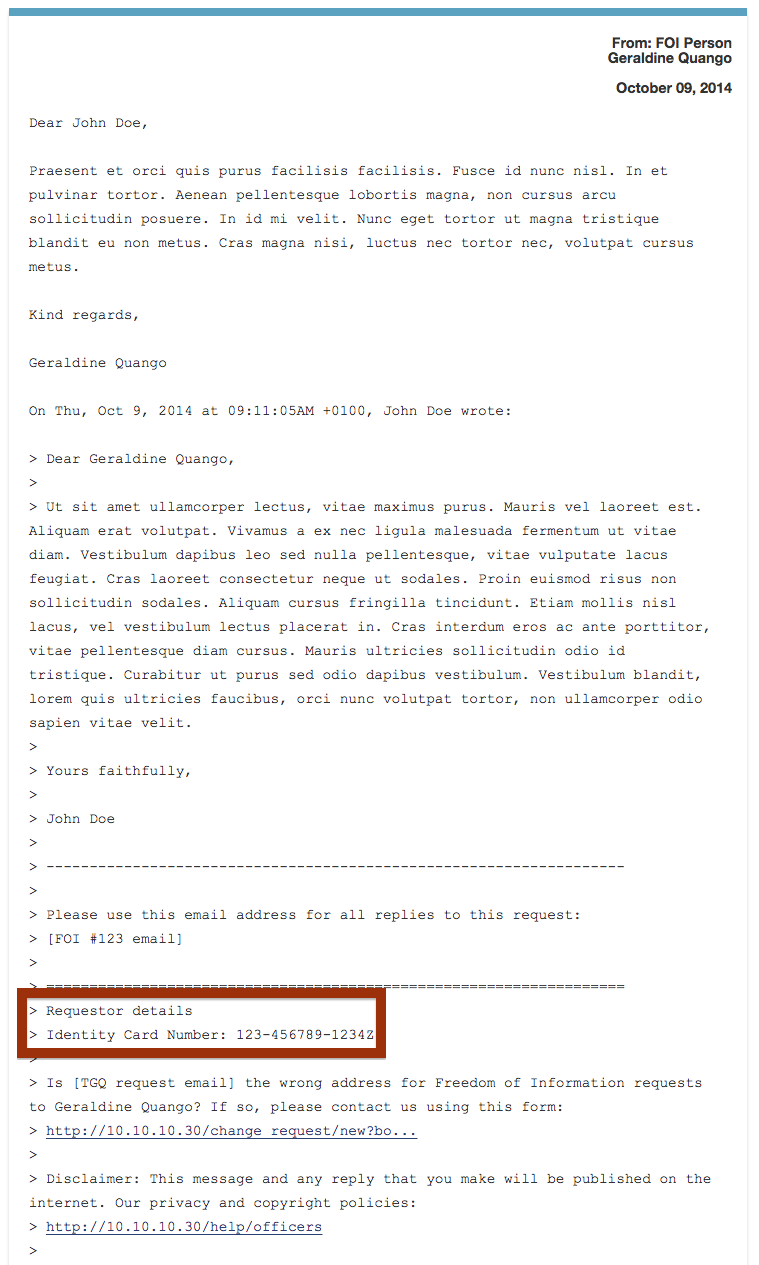
When the authority replies (by email), it’s unlikely that they will remove the quoted section of the email, which contains the requester’s ID number. This is a typical circumstance for redaction — we want to prevent Alaveteli displaying this information on the request page where the response (and other messages) are published.
One way to do this is to use the admin interface to add a censor rule to the individual request, like this:
- text:
123-456789-1234Z - replacement text:
REDACTED - scope: this request
…but this is an unsatisfactory solution, because that the administrators would need to add such a rule to every request as new requests are created.
Instead, because we know that every request will contain the user’s ID number, we can add some code to automatically create such a censor rule.
In this case, we patch the User model with a callback that creates a censor
rule as soon as the user is created (or updated):
# THEME_ROOT/lib/model_patches.rb
User.class_eval do
after_save :update_censor_rules
private
def update_censor_rules
censor_rules.where(:text => identity_card_number).first_or_create(
:text => identity_card_number,
:replacement => _('REDACTED'),
:last_edit_editor => THEME_NAME,
:last_edit_comment => _('Updated automatically after_save')
)
end
end
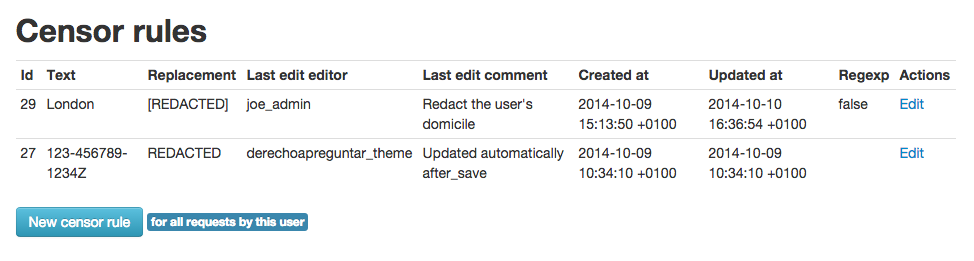
Administrators can see the new censor rule in the admin interface:
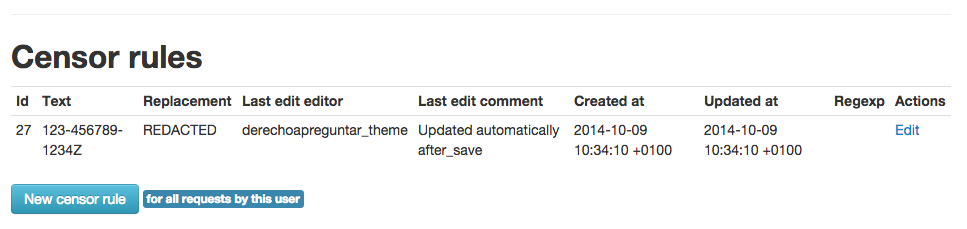
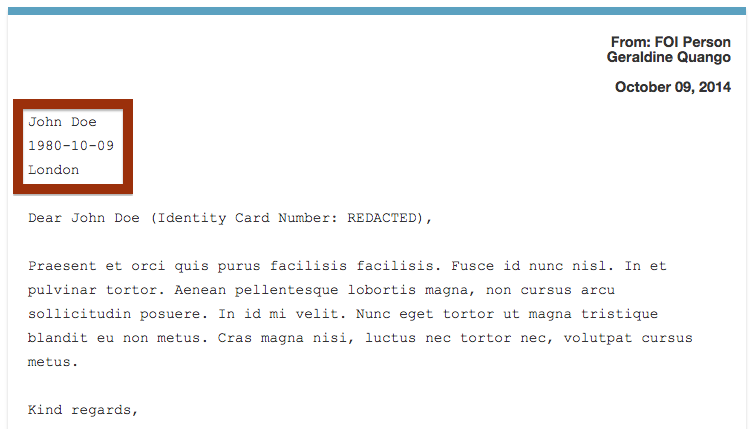
So now the ID number gets redacted:
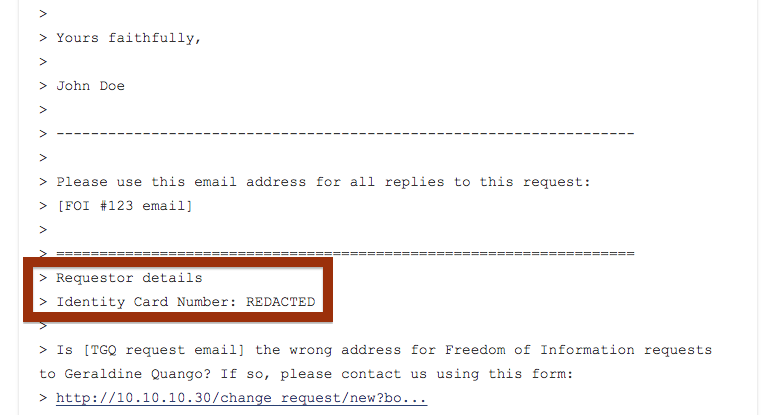
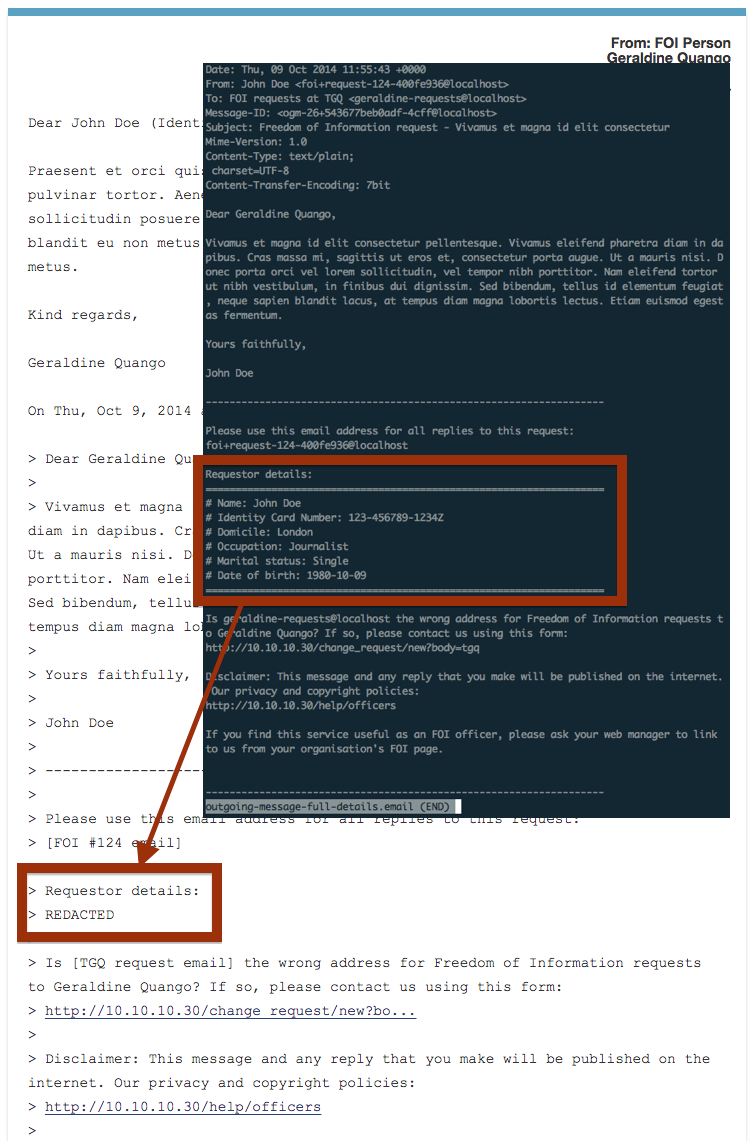
Because censor rules apply to the whole of every message, the ID number also gets redacted if the public body quote it anywhere in the main email body:
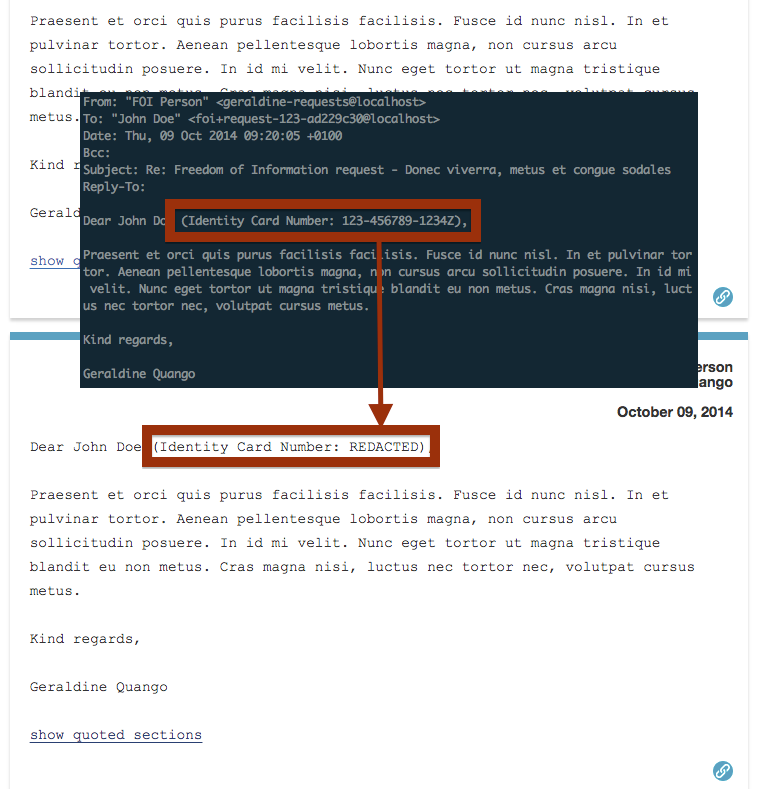
A censor rule added to a user gets applied to all correspondence on requests created by that user (that is, messages that are sent or received). But it does not get applied to annotations made by the user.
For example, if the public body was to remove the hyphens from the ID number it would not be redacted (because the censor rule does include them):
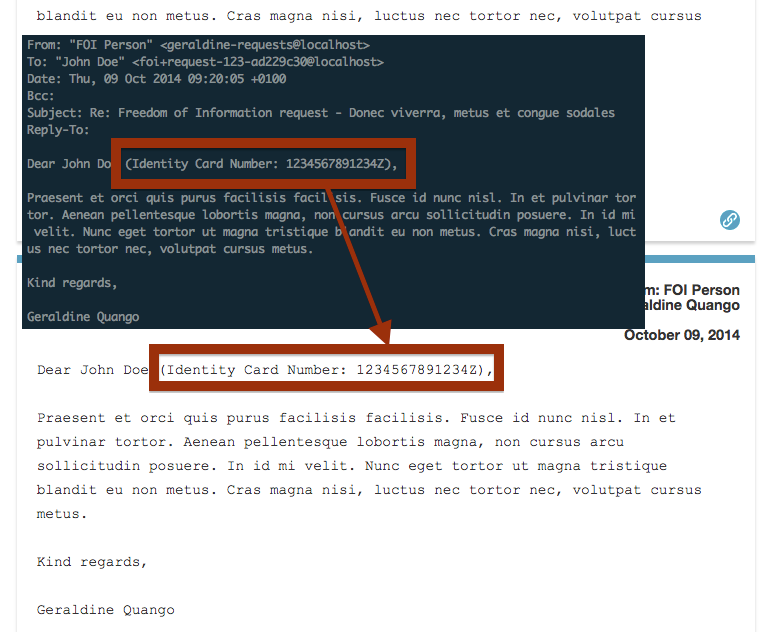
Alaveteli also attempts to redact the text from any attachments. It can only do this if it can find the exact string, which is not always possible in binary formats such as PDF or Word.
Alaveteli can usually redact the sensitive information when converting a PDF or text based attachment to HTML:
In contrast, this PDF does not contain the string in the raw binary so the redaction is not applied when downloading the original PDF document:

Redacting the “General Law” (personal details)
The General Law information is much harder to automatically redact. It is not as well-structured, and the information is unlikely to be unique to the user (for example, Domicile: London).
We add the General Law information to the initial request template in the same way as we did for the ID number:
<%= _('Requestor details') %>:
<%-# !!!IF YOU CHANGE THE FORMAT OF THE BLOCK BELOW, ADD A NEW CENSOR RULE!!! -%>
===================================================================
# <%= _('Name') %>: <%= @user_name %>
# <%= _('Identity Card Number') %>: <%= @user_identity_card_number %>
<% @user_general_law_attributes.each do |key, value| %>
# <%= _(key.humanize) %>: <%= value %>
<% end %>
===================================================================
Note that the information is now contained in a specially formatted block of text.
This allows a censor rule to match the special formatting and remove anything contained within. This rule is global, so it will act on matches in all requests.
Because this is matching a pattern of text, rather than an exact string, this censor rule uses a regular expression.
={67}\s*\n(?:[^\n]*?#[^\n]*?: ?[^\n]*\n){3,10}[^\n]*={67}
The regular expression broadly describes this pattern:
- two lines of sixty-seven equals signs (
=), with this in between: - between three and ten (inclusive) lines that:
- start with a hash (
#) - have something (without any newlines) followed by a colon (
:) - followed by some data on the same line
- start with a hash (
The code, in the theme’s lib/censor_rules.rb, looks like this:
# THEME_ROOT/lib/censor_rules.rb
# If not already created, make a CensorRule that hides personal information
regexp = '={67}\s*\n(?:[^\n]*?#[^\n]*?: ?[^\n]*\n){3,10}[^\n]*={67}'
unless CensorRule.find_by_text(regexp)
Rails.logger.info("Creating new censor rule: /#{regexp}/")
CensorRule.create!(:text => regexp,
:replacement => _('REDACTED'),
:regexp => true,
:last_edit_editor => THEME_NAME,
:last_edit_comment => 'Added automatically')
end
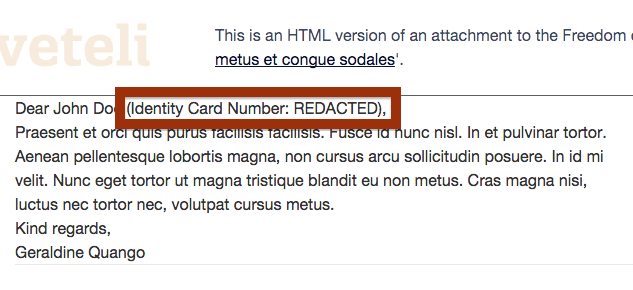
For example, here the authority has revealed the user’s date of birth and domicile:
Its really difficult to add a censor rule to remove this type of information, because it’s so general. One approach might be to remove all mentions of the user’s date of birth, but you would have to account for every type of date format. Likewise, you could redact all occurrences of the user’s domicile, but if they ask a question about their local area (which is very likely) the request would become unintelligible.
Here the redaction has been applied but there is no way of knowing the context that the use of the sensitive word is used.